My new toy: Openwebui First Steps
Once I got hardware-accelerated AI working under Linux on my AI mini workstation from HP, my next goal was to make it easier to use. From this blog, you can read about my initial experiments with Open WebUI on Fedora Linux.
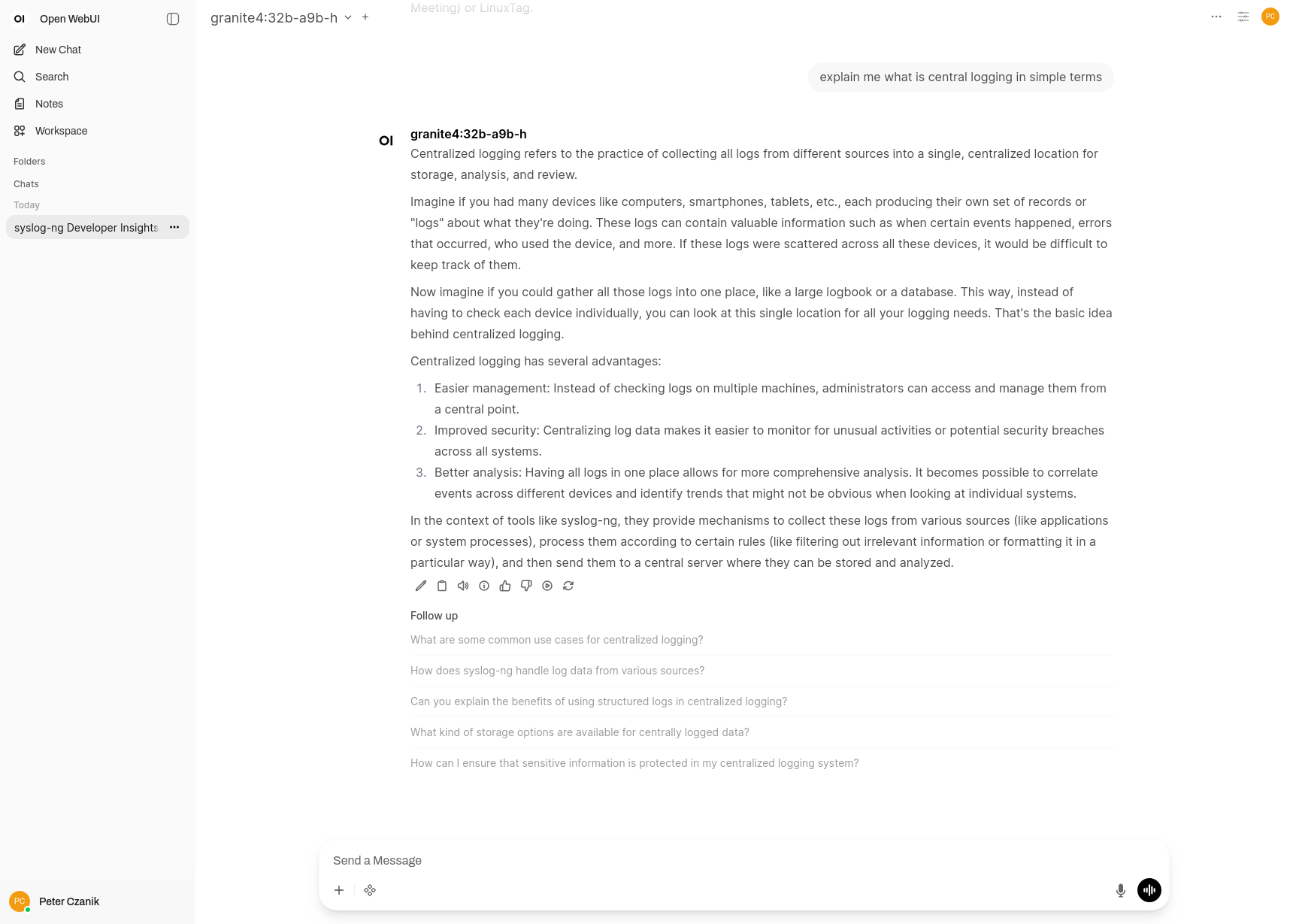
Open WebUI talking about central log collection :-)
Everything in containers
As Open WebUI is not yet available as a package in Fedora, my initial approach was to use containers. I found a Docker compose setup which was tested on Fedora Linux 43 according to its documentation: https://github.com/jesuswasrasta/ollama-rocm-webui-docker. As I (also) use Fedora 43, it sounded like a good choice.
It worked; however, I quickly realized that hardware acceleration for AI was not working. Instead of that, most CPUs were running close to 100%. It was a good test for cooling: I could hear the miniature box from the next room through closed doors :-)
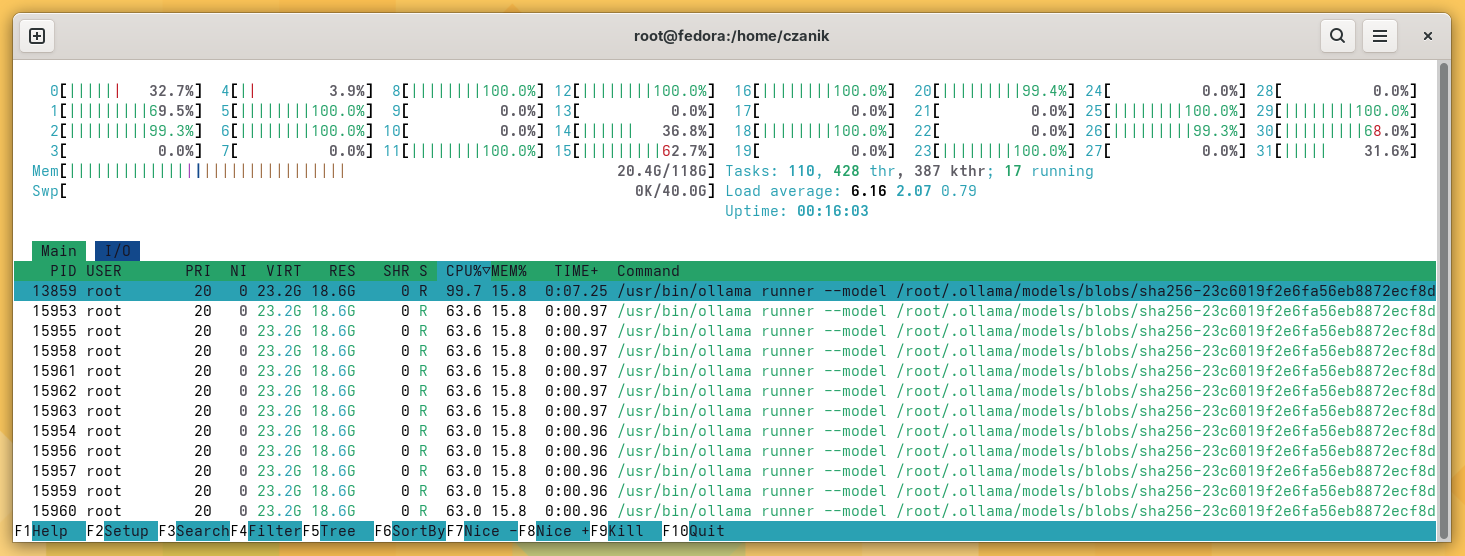
ollama eating CPU :-)
As it turned out, the content of the HSA_OVERRIDE_GFX_VERSION environment variable was incorrect. When I set it according to the docs, hardware acceleration still did not work. Removing the environment variable ollama found the hardware, but never answered a prompt anymore.
Ollama from the system
My next experiment was that I kept using Open WebUI from the container, but I installed ollama from the Fedora package repository directly on the system. The good news? Some smaller models ran really fast, using hardware acceleration. The bad news: most models failed to load with an error message that the given model format is unknown.
Update to Fedora 44 beta
I guessed that ollama was too old in Fedora 43. Solution? Update the whole system to Fedora 44 beta. It seems to have helped. A lot more models work now, including the largest freely available Granite models from IBM.
Why Granite?
First of all: I’m an IBM Champion, and thus using IBM technologies is for granted. But also because I learned some background stories from a friend working at IBM on LSF, which makes it also a personal choice.
What I’ve been showing here is AI inferencing on my HP AI system. But before the model can be used (for inferencing), it needs to be trained. These models are trained on large, GPU rich conpute clusters. To get an idea of the scale of such clusters, you can learn more in this research paper (https://arxiv.org/abs/2407.05467). It duscusses the IBM Blue Vela system which supports IBMs’ GenAI mission. What’s interesting is the Blue Vela uses a more traditional HPC software stack including IBM LSF for workload management and Storage Scale (GPFS) for rapid access to large data sets.

AI in a miniature box :-)
This blog is part of a longer series about my adventures with my new machine and AI. You can reach me to discuss this blog on one of the contacts listed in the upper right corner. You can read the rest of the blogs under the toy tag.